布隆过滤器 Bloom Filter
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由Burton Howard Bloom提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
原理
如果想判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。
这时候就可以利用哈希表这个数据结构(它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点)。这样一来,我们只要看看这个点是不是1就知道可以集合中有没有它了。这就是Bloom Filter的基本思想。
但这时,哈希冲突会是一个问题:假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m/100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们都在说谎,不过直觉上判断这种事情的概率是比较低的。简单的说这种多个Hash组成的数据结构就叫Bloom Filter。
初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。
![]()
为了表达S={X1, X2,…,Xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素X,第i个哈希函数映射的位置Hi(X)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
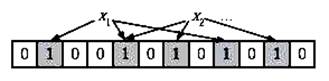
在判断Y是否属于这个集合时,我们对Y应用k次哈希函数,如果所有Hi(Y)的位置都是1(1≤i≤k),那么我们就认为Y是集合中的元素,否则就认为Y不是集合中的元素。下图中Y1就不是集合中的元素。Y2或者属于这个集合,或者刚好是一个误判。

应用布隆过滤器时,只需要由用户决定要容纳的元素数n和希望的误判率p。然后通过以下公式:
![]()
计算出位数组的长度m,然后通过m,n计算出哈希函数的个数k。
![]()
布隆过滤器的优劣主要与哈希函数的质量相关,而且哈希函数之间的相关度越小越好,每个哈希函数本身的计算过程不要太复杂,不然会影响效率。理想情况下是取k个完全不相关的哈希函数,在不是很严格情况下,也可以通过一个哈希函数的参数变化产生k个不同的哈希函数,比如将i(1≤i≤k)作为参数参与哈希函数的计算。
应用场景
通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。例如邮件黑名单,爬虫url等处理。
优点
节约缓存空间(空值的映射),不再需要空值映射。
减少数据库或缓存的请求次数。
提升业务的处理效率以及业务隔离性。
缺点
存在误判的概率。常见的补救办法是在建立一个小的白名单。
传统的Bloom Filter不能作删除操作。
例子
import java.util.BitSet;
public class SimpleBloomFilter {
// DEFAULT_SIZE为2的25次方
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 不同哈希函数的种子,一般应取质数,seeds数据共有7个值,则代表采用7种不同的HASH算法
*/
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 };
// BitSet实际是由“二进制位”构成的一个Vector。假如希望高效率地保存大量“开-关”信息,就应使用BitSet.
// BitSet的最小长度是一个长整数(Long)的长度:64位
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* 哈希函数对象
*/
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
String value = "stone2083@yahoo.cn";
// 定义一个filter,定义的时候会调用构造函数,即初始化七个hash函数对象所需要的信息。
SimpleBloomFilter filter = new SimpleBloomFilter();
// 判断是否包含在里面。因为没有调用add方法,所以肯定是返回false
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
// 构造函数
public SimpleBloomFilter(){
for (int i = 0; i < seeds.length; i++) {
// 给出所有的hash值,共计seeds.length个hash值。共7位。
// 通过调用SimpleHash.hash(),可以得到根据7种hash函数计算得出的hash值。
// 传入DEFAULT_SIZE(最终字符串的长度),seeds[i](一个指定的质数)即可得到需要的那个hash值的位置。
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// 将字符串标记到bits中,即设置字符串的7个hash值函数为1
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
// 判断字符串是否已经被bits标记
public boolean contains(String value) {
// 确保传入的不是空值
if (value == null) {
return false;
}
boolean ret = true;
// 计算7种hash算法下各自对应的hash值,并判断
for (SimpleHash f : func) {
// &&是boolen运算符,只要有一个为0,则为0。即需要所有的位都为1,才代表包含在里面。
// f.hash(value)返回hash对应的位数值
// bits.get函数返回bitset中对应position的值。即返回hash值是否为0或1。
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/* 哈希函数类 */
public static class SimpleHash {
// cap为DEFAULT_SIZE的值,即用于结果的最大的字符串长度。
// seed为计算hash值的一个给定key,具体对应上面定义的seeds数组
private int cap;
private int seed;
public SimpleHash(int cap, int seed){
this.cap = cap;
this.seed = seed;
}
// 计算hash值的具体算法,hash函数,采用简单的加权和hash
public int hash(String value) {
// int的范围最大是2的31次方减1,或超过值则用负数来表示
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
// 数字和字符串相加,字符串转换成为ASCII码
result = seed * result + value.charAt(i);
// System.out.println(result+"--"+seed+"*"+result+"+"+value.charAt(i));
}
// System.out.println("result="+result+";"+((cap - 1) & result));
// System.out.println(414356308*61+'h'); 执行此运算结果为负数,为什么?
// &是java中的位逻辑运算,用于过滤负数(负数与进算转换成反码进行)。
return (cap - 1) & result;
}
}
}




暂无评论